Introducing Logrange
May 22, 2019 by Dmitry Spasibenko
What is Logrange?
Logrange is an open-source streaming database for aggregating application logs, metrics, audit logs and other machine-generated data from thousands of sources.
Logrange is built upon the following principles:
- Every piece of data has its value
- Writing data is inexpensive, regardless of volume It’s convenient to have
- One place for storing data(logs, metrics, audit, etc.)
- Store first, process later
There are number of cases where Logrange could be useful:
- Log data aggregation and search
- Metrics collection
- Security alerts
- Anomalies prediction
- Incident investigation
- Hidden problems analysis
- etc.
Logrange is a game changer for monitoring the health and integrity of distributed systems. Why? Let's try to look into some details.
Distributed System Health and its Analysis
Modern distributed information systems have hundreds or even thousands of the system components(applications). Each component generates information in the form of application logs. There are also some metrics that can be monitored and recorded in real-time, known as machine-generated data, which are streaming in nature.
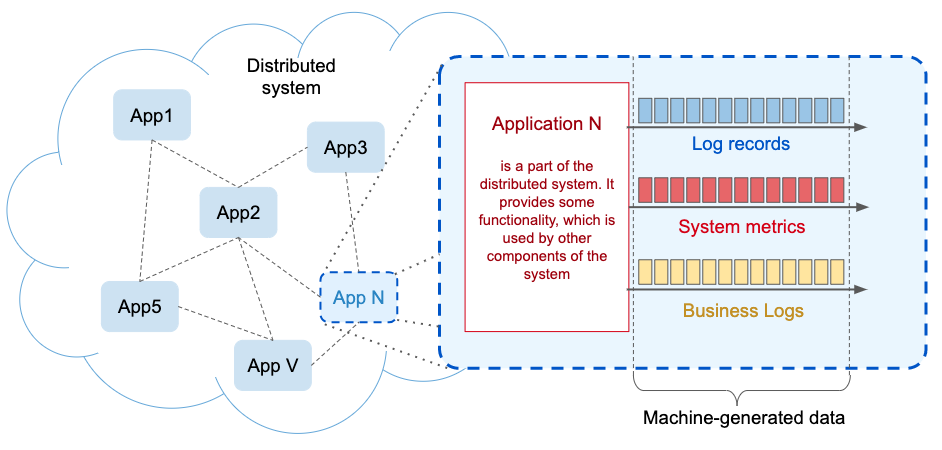
The streaming data is generated continuously by thousands of data sources, which typically sent in the data records simultaneously, and in small sizes. Despite of the fact that the records are small, due to the number of records the streaming data has very significant volume, which could be counted in hundred of megabytes per second(!).
To properly analyze distributed system data we need to:
- aggregate machine-generated data
- tailor our analysis of in accordance with a selected domain model
Data aggregation problem
Data aggregation becomes more of a challenging with greater volumes of machine-generated data.
For example, most log aggregation solutions offer powerful tools like full-text search that require data preprocessing (indexing). But data indexing is a resource-costly process, so for the tool to function at all, the number of stored logs is reduced. A full-text search may be not needed at all, but logs are cut anyway to avoid potentially high indexing costs. This doesn’t make much sense...
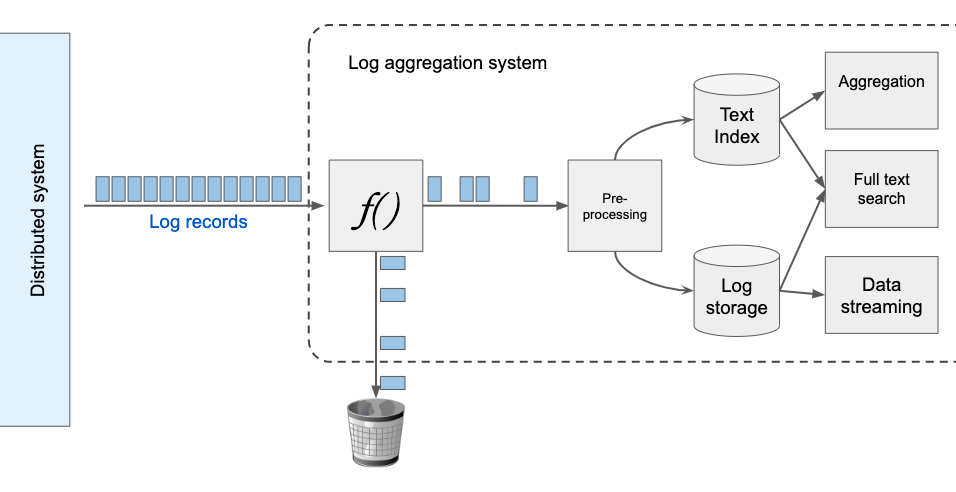
The conventional approach is to select "the most important" information and drop "unnecessary" data expensive so that the expense of information processing can be avoided
This might make sense if the system is predetermined and the methods for its analysis are known and clear. Unfortunately, this is rarely the case, so we can’t be sure whether the dropped information is truly unnecessary.
Data analysis problem
There are plenty of tools on the market designed to work with a specific type of streaming data. For example, some log aggregation solutions focus on collecting, indexing and persisting application logs to provide useful features like search. Other tools are designed to facilitate work with system metrics. They collect, persist and process resource consumption metrics. Providing alerts when a particular parameter reaches a threshold is a very useful feature.
All of these tools usually provide "full-stack" functionality for some specific type of data (verticals). This includes data collecting, pre-processing, persisting and providing features to the end user. Such an approach complicates data analysis of a distributed system because the it places the responsibility for integrating data from different sources on the end user.
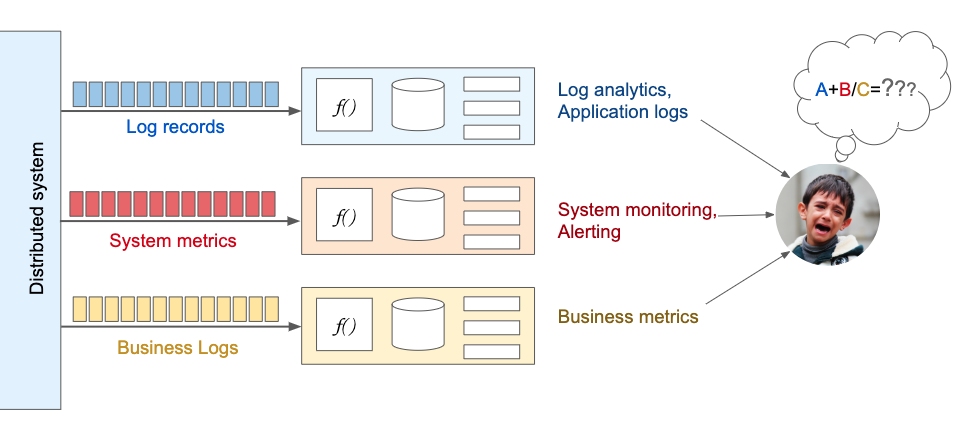
What makes Logrange different?
Logrange is designed to solve the aforementioned problems.
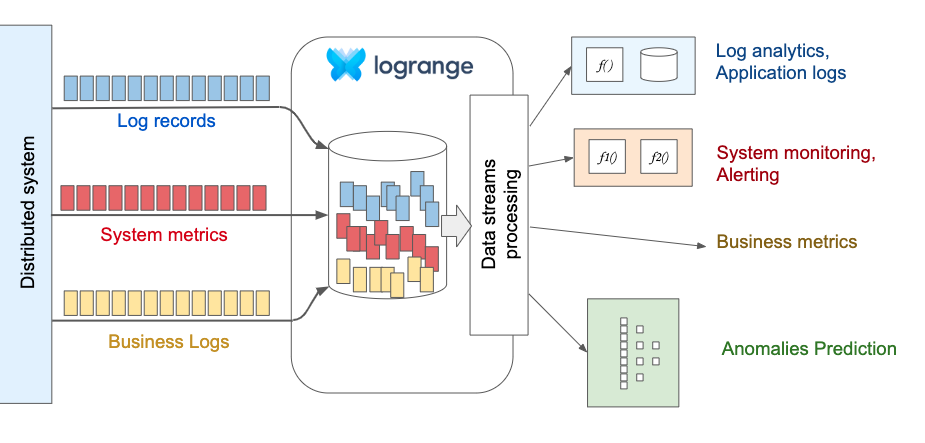
Persisting everything
Instead of trying to persist only "essential" data (we can never know what is essential), Logrange persists all the data. Having persisted all the data, we can now apply different types of processing to different data subsets. This allows us use a wide array of data analysis methods, build different models and more quickly develop an understanding of system behavior.
The cost of saving data is very low, if it turns out that some data sets are truly not needed, they could be removed at a later time.
Working with different types of data (verticals)
Having all the data in one place gives an advantage because there is no problem with the data integration from different data sources. For example, Logrange can keep system metrics, application and business logs or any other metrics in its database. Using this approach such tasks like finding correlation between log messages and system metrics could be easily solved.
Conclusion
Logrange strives to achieve the following goals:
- Persisting streaming data should be cheap.
- Any machine-generated data could be persisted into one place.
- Building advanced analytical tools easily on top of the collected data.
- Being open-source and secure.
- Run everywhere either in Cloud or On-Premise configurations.
- Easy to run and configure.
Logrange allows to persist every machine-generated data in one place with the purpose to perform comprehensive analysis of the data afterwards.
Talk to us!
If you want to learn more about Logrange and its use cases, take a look at our website.
If you need to have all logs from your system in one place, please do not hesitate to contact us or send us an email (mail@logrange.io).